
第2章では、AIが「探索・推論」「知識表現」「機械学習・ディープラーニング」という3つのアプローチを経てどう進化してきたかを俯瞰しました。
第3章は、その「機械学習」の中身に踏み込む章です。「AIはどうやって学ぶのか」を問う、第3の「木」。
この章でやることは、個々の手法を細かく暗記することではありません。「どの手法が何のためにあるのか」を説明できる状態を目指すのが目標です。この章が終わったとき、次の3つが言えていれば十分です。
- 教師あり・教師なし・強化学習の違いを説明できる
- 回帰問題と分類問題を区別できる
- 正解率だけでは評価が不十分な理由を説明できる
目次[閉じる]
- 1第3章の全体像
- 23-1|代表的な手法
- 2.1学習の3種類——問題の構造で使い分ける
- 2.2教師あり学習の手法──入力データと正解データをセットで学習する
- 2.3教師なし学習の手法──データの構造を自力で見つける
- 2.4強化学習──報酬を手がかりに、行動を学ぶ
- 33-2|モデルの選択・評価
- 4第3章のまとめ
- 5🔑 試験対策キーワード
- 6引っかけ・誤解まとめ
- 7次のステップ
第3章の全体像
第3章を一言で表すなら、「AIがどのように学び、どのように予測し、どのように改善するか」の仕組みを扱う章です。細かい手法に入る前に、まず全体の流れを押さえます。機械学習は次の6つのステップで進みます。
重要なのは、「学習 → 予測 → 評価 → 改善」が一連のサイクルであるという点です。この流れを頭に入れておくと、個々の手法や用語の役割がつながります。
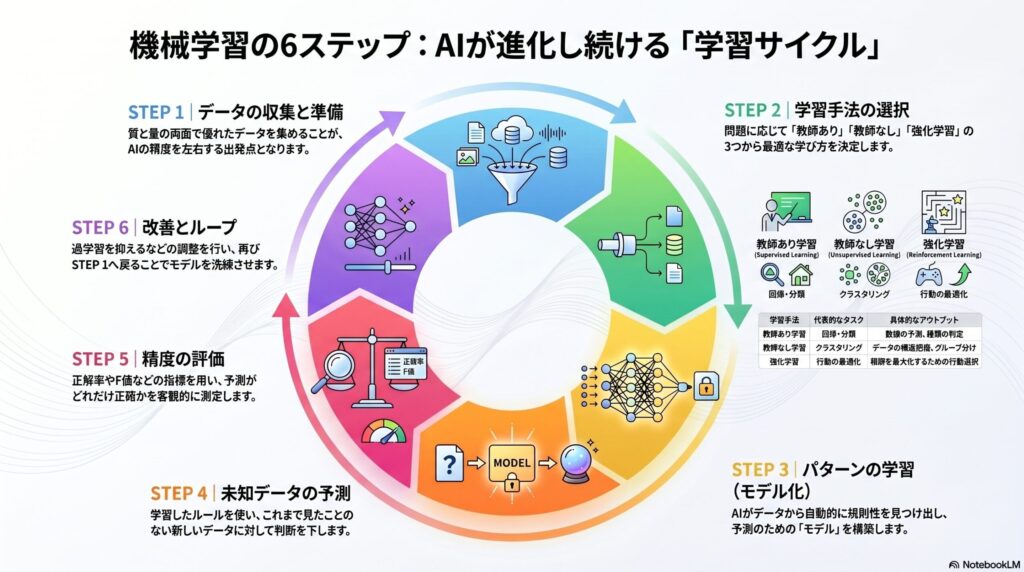
- データを集める
機械学習は、データがなければ何も始まりません。まず学習の材料となるデータを準備します。過去の売上データ・メールと迷惑メールのラベル・ユーザーの行動履歴など、データの質と量が、その後の学習精度を大きく左右します。
- 学び方を決める
問題の構造によって、適した学び方が変わります(3-1節)。教師あり学習(正解ラベル付きのデータで、入出力の関係を学ぶ)・教師なし学習(正解なしで、データそのものの構造をつかむ)・強化学習(行動と報酬のフィードバックで、最適な行動を学ぶ)の3つから選びます。
- パターンを学習する
集めたデータから規則(ルール)を見つけるのが学習フェーズです。このとき使われる仕組みをモデルと呼びます。回帰(数値を予測する)・分類(種類を判定する)・クラスタリング(グループに分ける)の3系統があります。AIは人があらかじめ決めていないルールをデータから自動で見つけ出します。
- 予測する
学習したルールを使って、新しいデータに対して判断を行います。「このメールは迷惑メールか」「来月の売上はいくらか」「このユーザーはどのグループに属するか」——未知データへの判断が、機械学習の目的です。
- 正しいか評価する
予測結果がどれだけ正確かを確認します。評価は、学習に使っていない未知のデータで行うことが重要です(3-2節)。正解率・適合率・再現率・F値(分類問題)/MSE・RMSE・MAE(回帰問題)/ROC曲線・AUC(確率出力のモデル)などの指標を使います。
- 改善する(過学習への対応)
評価をもとにモデルや学習方法を見直します。代表的な失敗が過学習(オーバーフィッティング)——訓練データに合わせすぎてしまい、未知のデータに対して正しく予測できなくなる状態です。評価の結果をもとに①に戻り、このサイクルを繰り返すことでモデルの精度が上がっていきます。
データから学び、未知データを予測し、評価して改善する。
3-1|代表的な手法
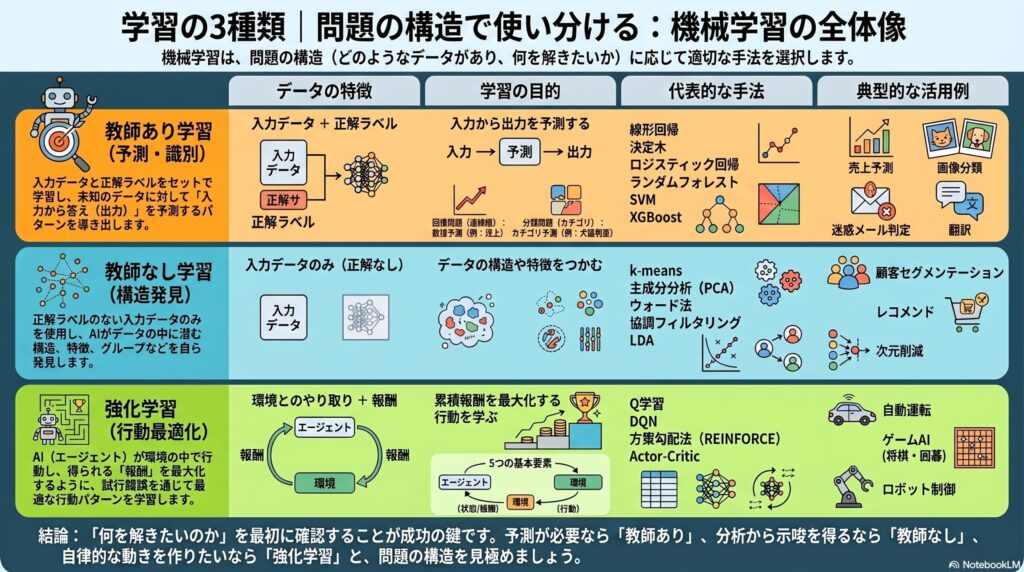
学習の3種類——問題の構造で使い分ける
機械学習と一口に言っても、「何を解きたいか」によってアプローチが3つに分かれます。どれが優れているかという話ではなく、問題の構造に応じて使い分けるものです。
| 種類 | データの特徴 | 学習の目的 | この章で扱う代表的な手法 | 典型例 |
|---|---|---|---|---|
| 教師あり学習 | 入力と正解ラベルがセット | 入出力のパターンを学ぶ | 線形回帰・ロジスティック回帰・決定木・ランダムフォレスト・ブースティング(AdaBoost・XGBoost)・SVM・自己回帰モデル | 売上予測・画像分類・翻訳 |
| 教師なし学習 | 入力のみ(正解なし) | データの構造・特徴をつかむ | k-means・ウォード法・主成分分析(PCA)・協調フィルタリング・トピックモデル(LDA) | 顧客セグメント分析・次元削減・レコメンド |
| 強化学習 | 環境からの報酬フィードバック | 累積報酬を最大化する行動を学ぶ | エージェント・環境・状態・行動・報酬の枠組み(具体的なアルゴリズムは第6章) | 自動運転・ゲームAI |
教師あり学習の手法──入力データと正解データをセットで学習する
教師あり学習は、入力データと正解データの関係を学習し、未知のデータに対して予測を行う手法です。G検定ではまず、予測したいものが数値なのか、それともカテゴリなのかを見分けることが重要です。
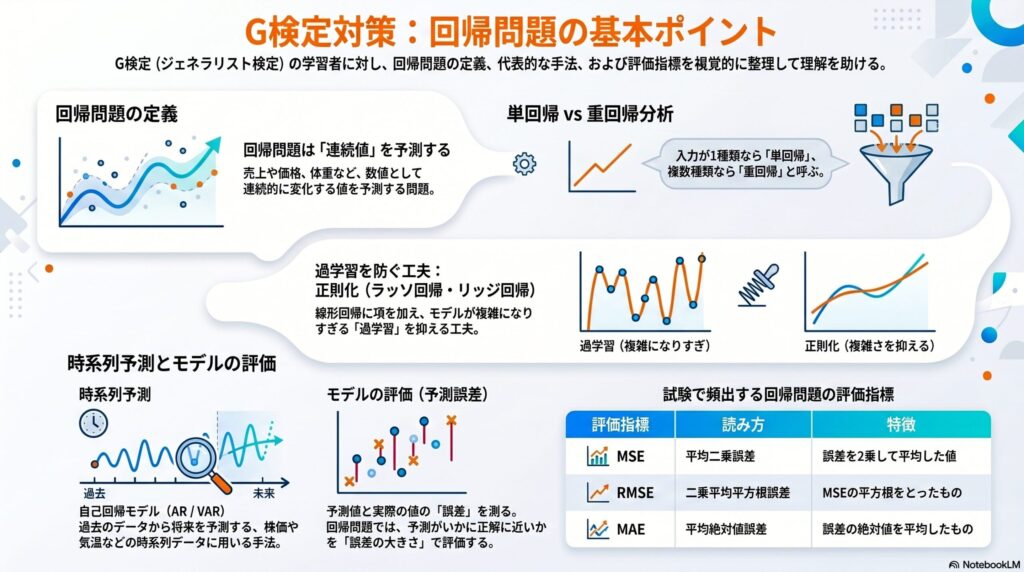
回帰問題──売上や気温のような「連続値」を予測する
回帰問題は、売上、気温、価格、体重のように、数値として連続的に変化する値を予測する問題です。G検定では「何kgか」「いくらか」「どのくらいか」を予測する場合は、まず回帰問題として考えます。
線形回帰──データに当てはまる直線で数値を予測する
最もシンプルな回帰問題の手法が線形回帰です。データの分布があったとき、そこに最もよく当てはまる直線、つまり回帰直線を引き、新しい入力に対して数値を予測します。
例えば、身長と体重の関係を直線で表し、「身長170cmなら体重は何kgか」を予測するイメージです。入力が1種類なら単回帰分析、複数種類なら重回帰分析といいます。
また、線形回帰に過学習を抑える正則化項を加えた手法として、ラッソ回帰とリッジ回帰があります。
自己回帰モデル──過去のデータから現在や将来の値を予測する
株価、気温、通信量のように、時間軸に沿って並んだデータを時系列データといいます。自己回帰モデル(ARモデル)は、過去のデータが現在の値にどれだけ影響しているかを重みとして学習し、現在や将来の値を予測する手法です。
入力が複数種類の時系列データになる場合は、ベクトル自己回帰モデル(VARモデル)といいます。
分類問題──犬か猫か、正常か異常かのような「カテゴリ」を予測する
分類問題は、犬か猫か、迷惑メールか通常メールか、正常品か不良品かのように、データをあらかじめ決められたカテゴリに分ける問題です。G検定では「どちらに属するか」「何に分類されるか」を問う場合は、分類問題として考えます。
ロジスティック回帰──名前は「回帰」でも分類問題に使う
ロジスティック回帰は、名前に「回帰」とありますが、分類問題に使う手法です。ここはG検定で引っかけられやすい重要ポイントです。
ロジスティック回帰では、出力にシグモイド関数を用いて、モデルの出力を0から1の確率に変換します。例えば「スパムメールである確率が0.8なのでスパムと判定する」といった使い方です。
2種類に分類する場合は2クラス分類、3種類以上に分類する場合は多クラス分類といいます。多クラス分類では、シグモイド関数ではなくソフトマックス関数を用います。
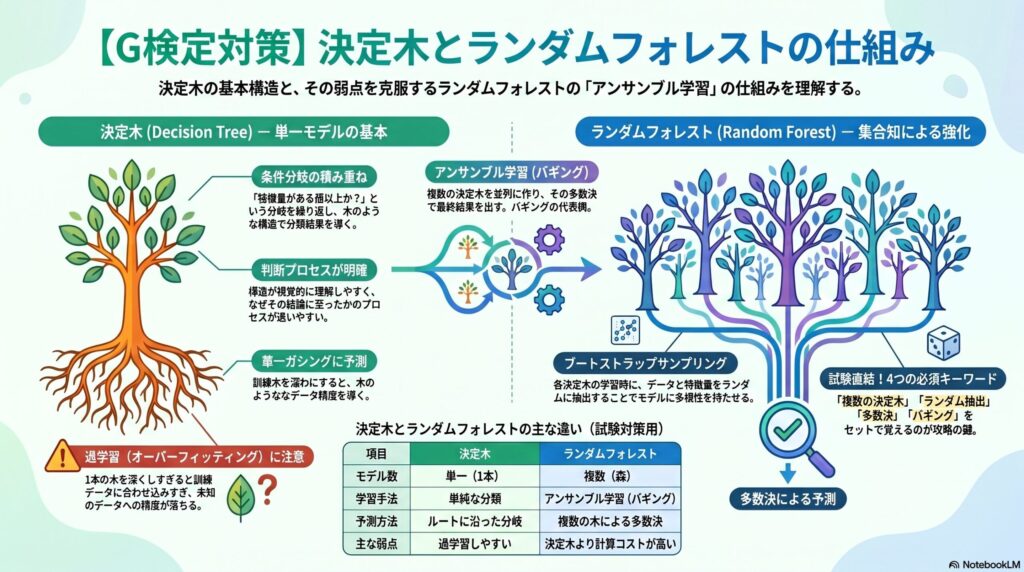
決定木──条件分岐を積み重ねて分類する
決定木は、「この特徴量の値は○○以上か?」という条件分岐を積み重ねて、最終的な分類結果を出す手法です。構造が木のように枝分かれするため、判断の流れを視覚的に理解しやすい特徴があります。
ただし、1本の決定木は訓練データに合わせ込みすぎて、過学習を起こしやすいという弱点があります。
ランダムフォレスト──複数の決定木を多数決でまとめる
ランダムフォレストは、複数の決定木を作り、それぞれの予測結果を多数決でまとめる手法です。1本の決定木に頼るのではなく、複数の木の集合知で最終判断を行います。
各決定木では、特徴量とデータをランダムに抽出します。このように、一部のデータをランダムに取り出して学習する方法をブートストラップサンプリングといいます。
複数のモデルを組み合わせる学習法をアンサンブル学習といい、ランダムフォレストはその中でも並列に複数モデルを作るバギングの代表例です。
ブースティング──誤りを次のモデルで重点的に学習する
ブースティングもアンサンブル学習の一種です。バギングが複数のモデルを並列に作るのに対し、ブースティングはモデルを直列、つまり逐次的に作ります。
直前のモデルが誤認識したデータを、次のモデルで重点的に学習させることで、誤りを減らしながら精度を上げていきます。代表的な手法にAdaBoostがあります。
また、前のモデルの予測誤差そのものを次のモデルが学習する手法が勾配ブースティングです。これを高速化した代表的なアルゴリズムがXGBoostです。
ブースティングは、バギングより学習に時間がかかる傾向がありますが、予測精度は高くなりやすいという特徴があります。
サポートベクターマシン(SVM)──マージンを最大化する境界線で分類する
SVM(サポートベクターマシン)は、異なるクラスのデータ点との距離、つまりマージンが最大になる境界線を求めて分類する手法です。この考え方をマージン最大化といいます。
データが直線では分類できない場合は、高次元の空間に写像して分類できるようにします。この写像に使う関数をカーネル関数、計算を効率化するテクニックをカーネルトリックといいます。
- ロジスティック回帰は回帰問題に使う手法ですか?
-
いいえ。名前に「回帰」とありますが、ロジスティック回帰は分類問題に使う手法です。G検定では非常に引っかけられやすいポイントです。
- シグモイド関数とソフトマックス関数はどう使い分けますか?
-
2クラス分類ではシグモイド関数、多クラス分類ではソフトマックス関数を使います。G検定では「2クラスか、多クラスか」で整理すると混乱しにくくなります。
- ランダムフォレストとブースティングの違いは何ですか?
-
ランダムフォレストは複数の決定木を並列に作るバギングの代表例です。一方、ブースティングはモデルを逐次的に作り、前のモデルの誤りを次のモデルで補正していきます。
- バギングとブースティングはどちらもアンサンブル学習ですか?
-
はい。どちらも複数のモデルを組み合わせるアンサンブル学習です。ランダムフォレストはバギング型、AdaBoostやXGBoostはブースティング型に分類されます。
- SVMの『マージン最大化』とは何ですか?
-
異なるクラスのデータとの距離(マージン)が、できるだけ大きくなるように境界線を引く考え方です。SVMは、このマージン最大化によって分類性能を高めます。
- 回帰問題と分類問題では、何が一番違いますか?
-
回帰問題は連続値を予測し、分類問題はカテゴリを予測します。「いくらか」を予測するのが回帰、「どちらに属するか」を予測するのが分類です。
教師なし学習の手法──データの構造を自力で見つける
教師なし学習は、正解データがない状態で、入力データそのものが持つ構造や特徴を見つける学習です。G検定では、教師なし学習をクラスタリング、次元削減、レコメンデーション・トピック分析の3系統で整理すると理解しやすくなります。
教師なし学習の3系統
- クラスタリング
似ているデータ同士をグループに分ける。代表例はk-means法、ウォード法、最短距離法。
- 次元削減
多すぎる特徴量を、分析しやすい少数の特徴量にまとめる。代表例はPCA、SVD、MDS、t-SNE。
- 推薦・トピック分析
ユーザーの好みや文書の話題を推定する。代表例は協調フィルタリング、コンテンツベースフィルタリング、トピックモデル、LDA。
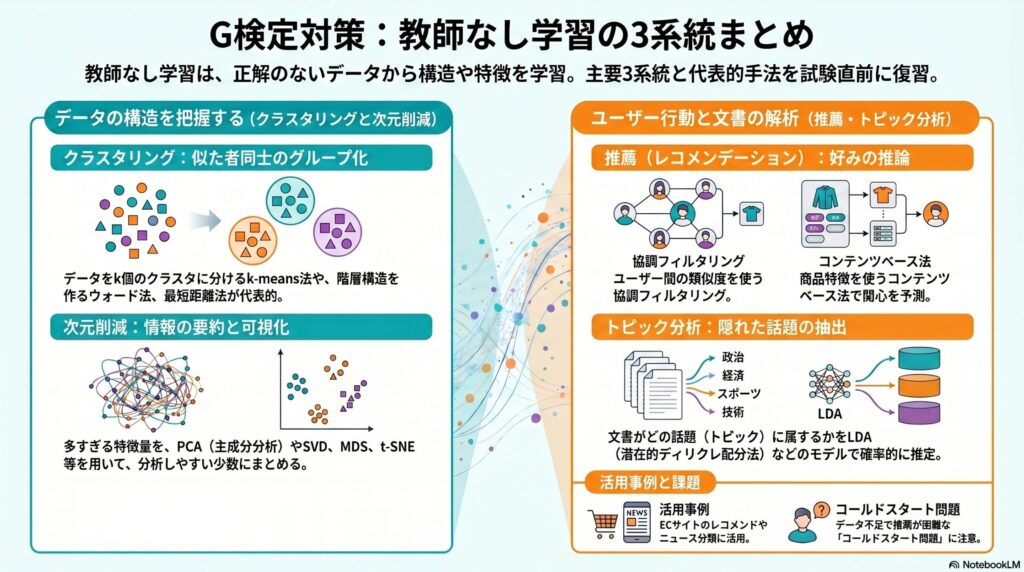
クラスタリング──似たデータをグループに分ける
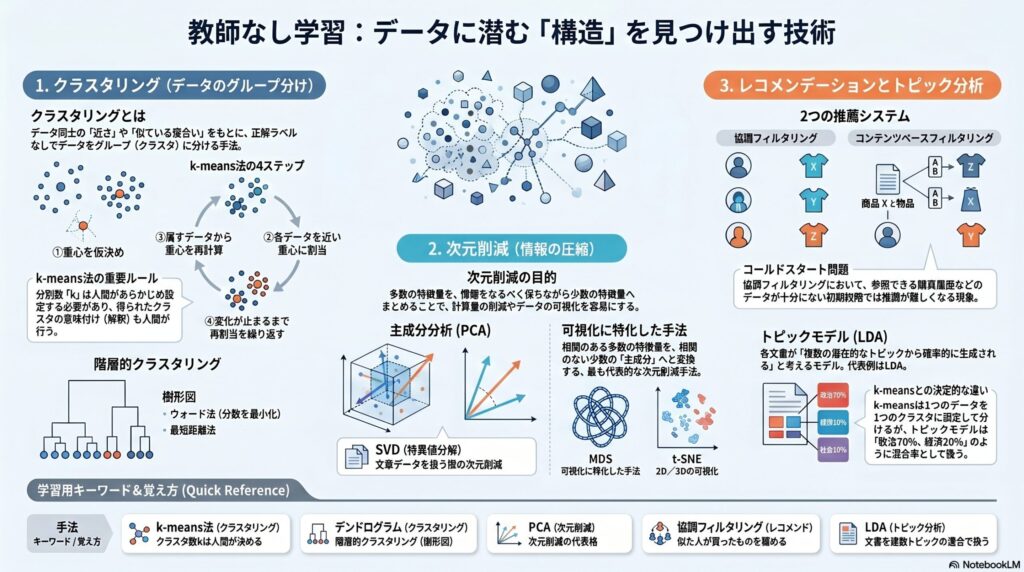
クラスタリングは、データ同士の近さや似ている度合いをもとに、データをグループへ分ける手法です。このグループをクラスタといいます。教師なし学習では正解ラベルがないため、得られたクラスタの意味を解釈するのは人間の役割です。
k-means法──k個のクラスタに分ける
k-means法は、データをk個のクラスタに分類する代表的なクラスタリング手法です。ここでのkは、あらかじめ人間が設定する値です。
- 重心を仮に決める
最初にk個の重心を設定し、各データを近い重心に割り当てる。
- 重心を計算し直す
各クラスタに属するデータから、新しい重心を求める。
- クラスタを振り分け直す
各データを、最も近い重心のクラスタへ再割り当てする。
- 変化が止まるまで繰り返す
重心の位置がほぼ変わらなくなるまで、重心計算と再割り当てを繰り返す。
階層的クラスタリング──クラスタの階層構造を作る
階層的クラスタリングは、データを単に横並びのグループに分けるだけでなく、クラスタ同士の階層構造まで求める手法です。代表的な手法にウォード法や最短距離法があります。
ウォード法は、クラスタ内のばらつきが小さくなるようにクラスタを作っていく手法です。最短距離法は、最も距離が近いデータやクラスタから順にまとめていく手法です。
階層的クラスタリングの結果は、デンドログラム(樹形図)で表されます。どの深さで区切るかによって、得られるクラスタの数や粒度が変わります。
次元削減──多すぎる特徴量を整理する
次元削減は、多数の特徴量を、情報をなるべく保ちながら少数の特徴量へまとめる考え方です。特徴量が多すぎると、分析が難しくなったり、計算量が増えたりするため、データを扱いやすくする目的で使われます。
主成分分析(PCA)──相関のある特徴量を少数の主成分にまとめる
主成分分析(PCA)は、相関を持つ多数の特徴量から、相関のない少数の特徴量へと変換する次元削減手法です。変換後の特徴量を主成分といいます。
PCAを使うと、データの分析をしやすくしたり、教師あり学習の入力に使う際の計算量を減らしたりできます。
SVD・MDS・t-SNE──文章分析や可視化に使われる手法
| 手法 | 押さえるポイント |
|---|---|
| SVD(特異値分解) | 文章データを扱う場合によく用いられる次元削減手法 |
| MDS(多次元尺度構成法) | 多次元データを2次元へ可視化する手法 |
| t-SNE | 2次元・3次元への可視化でよく用いられる手法 |
レコメンデーション──似た人・似た商品から推薦する
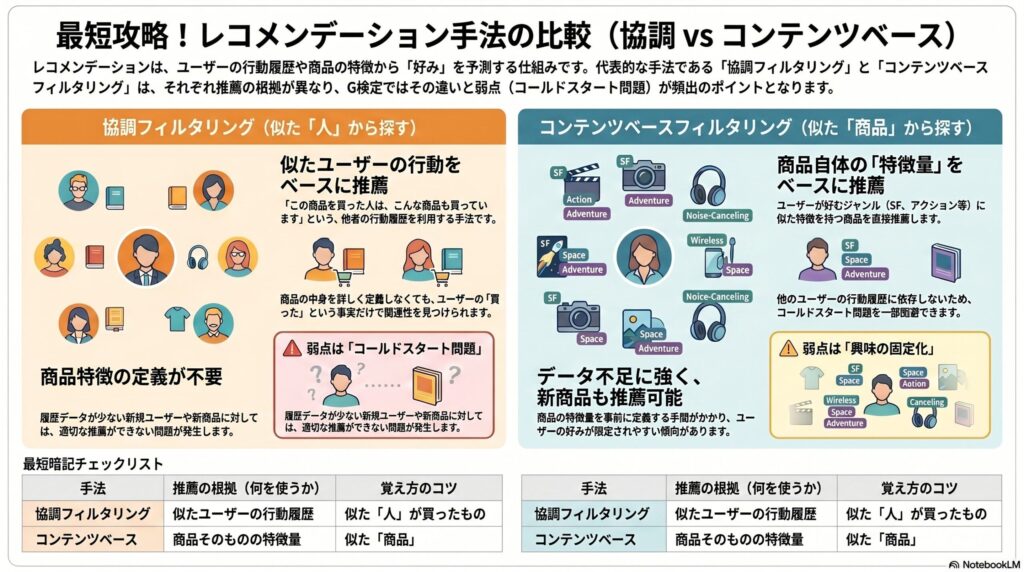
協調フィルタリング──似たユーザーの行動から推薦する
協調フィルタリングは、レコメンデーションに用いられる代表的な手法です。考え方は、「対象ユーザーは買っていないが、似たユーザーは買っている商品を推薦する」というものです。
例えば、ECサイトで「この商品を買った人は、こんな商品も買っています」と表示されるような推薦が、協調フィルタリングの代表的なイメージです。
ただし、他のユーザーの購買履歴など、参照できるデータが十分にないと推薦が難しくなります。この問題をコールドスタート問題といいます。
コンテンツベースフィルタリング──商品の特徴から推薦する
コンテンツベースフィルタリングは、ユーザー同士の類似ではなく、商品そのものの特徴量を使って推薦する手法です。対象ユーザーのデータがあれば推薦できるため、協調フィルタリングのコールドスタート問題を一部回避できます。
トピックモデル──文書を複数の話題の混合として扱う
トピックモデルは、文書データを対象に、各文書が複数の潜在的なトピックから確率的に生成されると考えるモデルです。文書を1つのカテゴリに固定するのではなく、「政治70%、経済20%、スポーツ10%」のように、複数トピックの混合として扱えます。
代表的な手法が、LDA(潜在的ディリクレ配分法)です。ニュース記事のテーマ分類、似た文章の推薦、ECサイトのレコメンドなどに応用されます。
- 教師なし学習は何を学習する手法ですか?
-
正解データを使わず、入力データそのものが持つ構造や特徴を学習する手法です。クラスタリング、次元削減、レコメンデーションなどに使われます。
- k-means法のkは何を表しますか?
-
分けたいクラスタの数です。kは自動で決まるのではなく、人間があらかじめ設定します。
- PCAは何のために使いますか?
-
PCAは次元削減のために使います。多数の特徴量を少数の主成分にまとめ、分析しやすくしたり、計算量を減らしたりします。
- 協調フィルタリングとコンテンツベースフィルタリングの違いは何ですか?
-
協調フィルタリングは、似たユーザーの行動から推薦します。コンテンツベースフィルタリングは、商品の特徴量から似た商品を推薦します。
強化学習──報酬を手がかりに、行動を学ぶ
強化学習を一言で言うと、「行動を学習する仕組み」です。教師あり学習のように正解データを直接与えるのではなく、試行錯誤の中で得られる報酬(スコア)を手がかりに、「どう行動すれば最終的に最も得をするか」を学習します。
強化学習の基本構造
強化学習では、エージェントが環境を観測し、行動し、その結果として報酬を受け取ります。この流れを何度も繰り返しながら、「どんな行動が得か」を学習していきます。
- 状態を観測
エージェントが現在の環境を観測する
- 行動を選択
現在の状態から、どの行動をとるか決定する
- 報酬を受け取る
行動の結果に応じてスコア(報酬)が与えられる
- 行動を改善
より高い報酬が得られるよう、次の行動を調整する
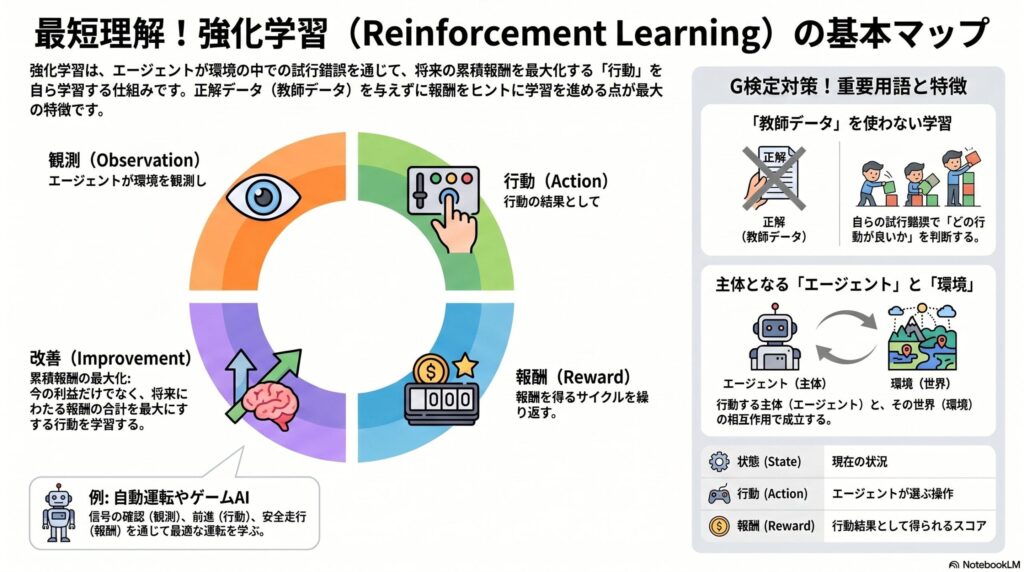
強化学習の5要素
| 要素 | 意味 | 自動運転での対応 |
|---|---|---|
| エージェント | 学習・行動する主体 | 車(AI) |
| 環境 | エージェントが置かれる場 | 道路・街 |
| 状態 | 現在の環境情報 | 周囲の車・歩行者・信号 |
| 行動 | エージェントの選択 | 進む・止まる・曲がる |
| 報酬 | 行動の良し悪しを示すスコア | 安全に走行できた度合い |
累積報酬と割引率(γ)
強化学習の目的は、将来にわたる累積報酬を最大化することです。ただし、将来の報酬は不確実なので、時間が遠い報酬ほど価値を小さくして考えます。
この「将来の報酬をどれくらい割り引くか」を調整する値が、割引率(γ)です。
探索と活用
強化学習では、「今わかっている最善手を使うべきか」、それとも「もっと良い方法がないか試すべきか」のバランスが重要になります。
| 考え方 | 意味 |
|---|---|
| 活用(Exploitation) | 今わかっている最善の行動を選ぶ |
| 探索(Exploration) | もっと良い行動がないか試す |
このバランスを調整する代表的な手法が、ε-greedy方策やUCB方策です。
- 強化学習は何を学習する仕組みですか?
-
強化学習は、報酬を手がかりに「どの行動をとれば最終的に得をするか」を学習する仕組みです。
- 教師あり学習と強化学習の違いは何ですか?
-
教師あり学習は正解データを学習します。一方、強化学習は正解を直接与えず、報酬を手がかりに行動を学習します。
- 強化学習で『探索』と『活用』とは何ですか?
-
探索は「もっと良い行動がないか試すこと」、活用は「今わかっている最善手を使うこと」です。強化学習では、このバランスが重要になります。
3-2|モデルの選択・評価
データの分割──「未知のデータ」を擬似的に作り出す
機械学習の目的は、手元のデータだけに当てはまるモデルを作ることではなく、未知のデータにも通用するパターンを学習することです。そこで、手元のデータの一部を評価専用に取り分け、擬似的な未知データとして扱います。
学習に使うデータを訓練データ、評価に使うデータをテストデータと呼びます。このようにデータを分割して評価する方法を交差検証といいます。
| 方法 | 概要 | 特徴 |
|---|---|---|
| ホールドアウト検証 | 全データを訓練データとテストデータに1回だけ分割する | シンプル。データが少ないと評価が偏る可能性がある |
| k-分割交差検証 | データをk個に分割し、1つずつテストデータにして評価を繰り返す | 評価の偏りを抑えやすい。ただし計算コストは増える |
さらに、訓練データを分割して検証データを用意することもあります。この場合、全データは訓練データ・検証データ・テストデータの3区分になります。モデルの調整は検証データで行い、最終評価だけテストデータで行う、という流れです。
| データ | 役割 |
|---|---|
| 訓練データ | モデルを学習させるためのデータ |
| 検証データ | モデルやハイパーパラメータを調整するためのデータ |
| テストデータ | 最終的な予測性能を確認するためのデータ |
評価指標(回帰問題)──誤差をそのまま数値で測る
回帰問題は、売上・気温・価格のような連続値を予測する問題です。分類問題のように「当たり・外れ」を明確に分けにくいため、予測値と実際の値の誤差を評価に使います。
| 指標 | 正式名称 | 特徴 |
|---|---|---|
| MSE | 平均二乗誤差 | 誤差を2乗して平均する。正負の誤差が打ち消し合わない |
| RMSE | 二乗平均平方根誤差 | MSEの平方根。元の単位と対応させやすい |
| MAE | 平均絶対値誤差 | 誤差の絶対値を平均する。MSEより外れ値の影響を受けにくい |
評価指標(分類問題)──混同行列で「当たり・外れ」を整理する
分類問題では、犬か猫か、正常か異常かのように、予測結果の「当たり・外れ」が比較的明確です。この組み合わせを整理する表が混同行列(confusion matrix)です。
| 実際:正(Positive) | 実際:負(Negative) | |
|---|---|---|
| 予測:正(Positive) | 真陽性(TP) | 偽陽性(FP) |
| 予測:負(Negative) | 偽陰性(FN) | 真陰性(TN) |
FPは、本当は負なのに正と予測した誤りです。統計用語では第一種過誤とも呼ばれます。FNは、本当は正なのに負と予測した誤りで、第二種過誤とも呼ばれます。
| 指標 | 計算 | 何を測るか | 重視すべき場面 |
|---|---|---|---|
| 正解率(Accuracy) | (TP+TN)÷全データ数 | 全体のうち正しく予測できた割合 | クラスの偏りが小さいとき |
| 適合率(Precision) | TP÷(TP+FP) | 「正」と予測したもののうち、本当に正だった割合 | 誤検出を減らしたいとき |
| 再現率(Recall) | TP÷(TP+FN) | 本当に正のものを、正しく正と予測できた割合 | 見逃しを減らしたいとき |
| F値(F measure) | 適合率と再現率の調和平均 | 適合率と再現率のバランス | 両方をバランスよく見たいとき |
適合率と再現率はトレードオフの関係になりやすい指標です。片方を上げようとすると、もう片方が下がる場合があります。そのバランスを1つの数値で見る指標がF値です。
正解率だけでは不十分な場面があります。たとえば、工場の不良品検出で10,000個中3個だけが不良品の場合、すべてを「良品」と予測しても正解率は99.97%になります。しかし、不良品は1個も見つけられていません。このようなクラス不均衡の問題では、再現率やF値などを確認する必要があります。
ROC曲線とAUC──閾値を動かしてモデルの実力を測る
ロジスティック回帰のように、モデルの出力が確率値で表される場合、「0.5以上なら正例」のように閾値を設定して分類します。この閾値を変えると、TP・FP・FN・TNの値も変わります。
閾値を0から1まで動かしながら、縦軸に真陽性率(TPR)、横軸に偽陽性率(FPR)をプロットしたものがROC曲線です。
| 用語 | 意味 |
|---|---|
| TPR | 真陽性率。再現率と同じ。TP÷(TP+FN) |
| FPR | 偽陽性率。本当は負のものを、誤って正と予測した割合。FP÷(FP+TN) |
| ROC曲線 | 閾値を変えたときのTPRとFPRの関係を表す曲線 |
| AUC | ROC曲線の下の面積。1に近いほど性能が高い |
ROC曲線が左上に近いほどモデルの性能が高く、その曲線の下の面積がAUC(Area Under the Curve)です。AUCは1に近いほど高性能、0.5はランダム予測と同等を示します。
過学習──訓練データだけに合わせ込みすぎる
訓練データに対する精度は高いのに、テストデータに対する精度が低い状態を過学習(オーバーフィッティング)といいます。モデルが訓練データのノイズや偶然の特徴まで学習してしまい、未知のデータに通用しなくなった状態です。
モデルの選択──シンプルさと精度のバランスを取る
モデルを複雑にすれば、訓練データへの当てはまりは良くなる可能性があります。しかし、複雑すぎるモデルはノイズまで表現してしまい、過学習を起こしやすくなります。
「必要以上に複雑な仮定を置くべきでない」という原則をオッカムの剃刀といいます。機械学習でも、必要以上に複雑なモデルを選ぶのではなく、説明力とシンプルさのバランスを取ることが重要です。
このバランスを定量的に評価する指標が情報量基準です。代表的なものに、AIC(赤池情報量基準)とBIC(ベイズ情報量基準)があります。
| 指標 | 意味 | 押さえるポイント |
|---|---|---|
| AIC | 赤池情報量基準 | モデルの当てはまりと複雑さのバランスを見る |
| BIC | ベイズ情報量基準 | データ数が多い場合に、パラメータ数へのペナルティが大きくなりやすい |
- モデルの性能は何で評価しますか?
-
未知データへの予測性能で評価します。そのため、手元のデータを訓練データとテストデータに分け、テストデータで最終評価します。
- ホールドアウト検証とk-分割交差検証の違いは何ですか?
-
ホールドアウト検証は1回だけ訓練データとテストデータに分割します。k-分割交差検証は、データをk個に分け、テストデータにする部分を入れ替えながら複数回評価します。
- 分類問題で正解率だけを見ると危険な場合はありますか?
-
あります。クラスに偏りがある場合、すべてを多数派に分類しても正解率が高く見えることがあります。この場合は、適合率、再現率、F値なども確認する必要があります。
- 適合率と再現率の違いは何ですか?
-
適合率は「正と予測したものがどれだけ本当に正だったか」です。再現率は「本当に正のものをどれだけ拾えたか」です。誤検出を減らしたいなら適合率、見逃しを減らしたいなら再現率を重視します。
- ROC曲線とAUCは何を見る指標ですか?
-
ROC曲線は、分類の閾値を変えたときのTPRとFPRの関係を見る曲線です。AUCはROC曲線の下の面積で、1に近いほどモデル性能が高いことを示します。
- 過学習とは何ですか?
-
訓練データに合わせ込みすぎて、未知データに対する性能が低くなる状態です。訓練データの精度は高いのにテストデータの精度が低い場合、過学習を疑います。
- AICとBICは何のための指標ですか?
-
AICとBICは、モデルの当てはまりと複雑さのバランスを見る情報量基準です。どちらも、パラメータ数が多すぎるモデルにはペナルティを与えます。
第3章のまとめ
混乱しやすい概念を対比表で整理します。
| 比較 | A | B | 判断のポイント |
|---|---|---|---|
| 回帰 vs 分類 | 数値(連続値)を予測 | カテゴリ(離散値)を予測 | 答えが数値か、種類か |
| バギング vs ブースティング | 並列でモデルを作り多数決 | 逐次で誤りを重点学習 | 学習の順序が並列か直列か |
| 適合率 vs 再現率 | 予測の正確さ(誤判定を防ぐ) | 見逃しの少なさ(漏れを防ぐ) | 何を重視するかで使い分ける |
| ホールドアウト vs k-分割交差検証 | 1回だけ分割・シンプル | k回繰り返す・偏りを抑える | データ量が少ないならk-分割 |
| AIC vs BIC | パラメータ数にペナルティ | データ数が多いほど厳しく評価 | どちらを使うかの明確な基準はない |
第3章で理解しておくべきことを3行に絞るとこうなります。
- 機械学習は「教師あり・教師なし・強化学習」の3種類に分かれ、問題の構造に応じて使い分ける。教師あり学習はさらに「回帰か分類か」を確認してから手法を選ぶ。
- 教師なし学習はデータの構造をつかむ手法群(クラスタリング・次元削減・レコメンデーション・トピック分析)で、それぞれの用途の違いを区別できるようにしておく。
- モデルの性能は「未知データへの予測力」で測る。交差検証でデータを分割し、課題に合った評価指標(MSE・正解率・再現率・F値・AUC)を選ぶことが重要。過学習への対策とAIC/BICによるモデル選択の考え方も試験頻出。
🔑 試験対策キーワード
ここからは「葉」のフェーズです。
「葉」のフェーズの意味が「?」な方は、先に「森 → 木 → 枝 → 葉」の学習アプローチを確認してから戻ってきてください。
そうすることで、あなたが手戻りするタイムロスを防げます。
さて、話を戻します。
まず、Mainキーワードを10秒で説明できる状態にすることを目指してください。
キーワードの記憶定着にはAnkiなど、いつでも、どこでも使えるアプリの活用をおすすめします。
Subは問題を解いていて「迷った・止まった」語句だけ追加していきます。
「説明できる」=「選択肢で判断できる」状態です。
■ Main(説明の軸:10秒で言えるようにすること)
Mainは23語です。この23語が説明できれば、第3章の試験問題は8割対応できます。
| キーワード | 10秒で言えるようにすること |
|---|---|
| 教師あり学習 | 入力と正解ラベルがセットのデータで、入出力のパターンを学ぶ手法。 |
| 教師なし学習 | 正解ラベルなしで、データそのものの構造や特徴をつかむ手法。 |
| 強化学習 | 報酬を手がかりに、累積報酬を最大化する行動を学ぶ仕組み。正解データは与えない。 |
| 回帰問題 | 売上・気温のような連続値(数値)を予測する問題。評価指標はMSE・RMSE・MAEなど。 |
| 分類問題 | 犬か猫か・正常か異常かのようにカテゴリを判定する問題。評価指標は混同行列ベース。 |
| 線形回帰 | データに最もよく当てはまる直線を引いて数値を予測する、最もシンプルな回帰手法。 |
| ロジスティック回帰 | 名前に「回帰」とつくが分類問題に使う手法。シグモイド関数で出力を確率に変換する。 |
| 決定木 | 「はい/いいえ」の条件分岐を積み重ねて分類する手法。1本では過学習しやすい。 |
| ランダムフォレスト | 複数の決定木を作り多数決する手法。アンサンブル学習(バギング)の代表例。 |
| ブースティング | 前のモデルが誤認識したデータを重点学習して逐次精度を上げるアンサンブル手法。バギングとの違いは「逐次」。 |
| SVM | 異なるクラスのデータ点との距離(マージン)が最大になる境界線を求める分類手法。 |
| k-means法 | 重心を繰り返し計算しデータをk個のクラスタに分類する教師なし学習の手法。kは人間が設定する。 |
| PCA(主成分分析) | 特徴量間の相関をもとに次元削減する手法。多数の特徴量を少数の主成分に変換する。 |
| 交差検証 | データを訓練用とテスト用に分けてモデルの性能を評価する方法。訓練データだけで評価してはいけない。 |
| 過学習 | 訓練データだけに最適化されすぎて、未知データに通用しなくなった状態(オーバーフィッティング)。 |
| 混同行列 | 分類の予測結果をTP・FP・FN・TNで整理した表。適合率・再現率・F値の計算の基礎。 |
| 適合率 | 「正」と予測したうち、本当に正だった割合。誤検出を減らしたいときに重視する。 |
| 再現率 | 本当に正のものを、正しく「正」と予測できた割合。見逃しを減らしたいときに重視する。 |
| F値 | 適合率と再現率の調和平均。両方のバランスを1つの数値で見る指標。 |
| ROC曲線 | 閾値を変えながら真陽性率(TPR)と偽陽性率(FPR)をプロットした曲線。左上に近いほど高性能。 |
| AUC | ROC曲線の下の面積。1に近いほどモデルの識別能力が高い。0.5はランダムと同等。 |
| AIC | 赤池情報量基準。モデルの当てはまりと複雑さのバランスを定量評価する指標。 |
| BIC | ベイズ情報量基準。AICと同じくモデル選択の指標で、データ数が多いほどペナルティが大きくなる。 |
■ Sub(補助説明:問題で迷ったら追加する)
| キーワード | 一言で言えること |
|---|---|
| AdaBoost | ブースティングの代表的手法。前のモデルの誤認識データに重みをかけて次を学習させる。 |
| XGBoost | 勾配ブースティングを高速化したアルゴリズム。 |
| アンサンブル学習・バギング | 複数モデルを組み合わせる手法の総称。並列型がバギング(ランダムフォレスト)、逐次型がブースティング。 |
| カーネルトリック・カーネル関数 | SVMで直線分離できないデータを高次元に写像して線形分離できるようにするテクニック。 |
| 自己回帰モデル(ARモデル) | 時系列データを対象に、過去の値を重み付きで合算して現在を予測する回帰手法。 |
| VARモデル | ARモデルを複数種類の時系列データに拡張したもの。 |
| ウォード法 | クラスタ内のばらつきが小さくなるように統合する階層的クラスタリング手法。 |
| デンドログラム | 階層的クラスタリングの結果を表す樹形図。問題に出てきたら階層型クラスタリングを疑う。 |
| LDA(トピックモデル) | 文書を複数トピックの確率的な混合として扱うクラスタリング手法の代表。 |
| SVD(特異値分解) | 文章データを扱う場合によく用いられる次元削減手法。 |
| MDS・t-SNE | 多次元データを2〜3次元に可視化する手法。 |
| コンテンツベースフィルタリング | 商品の特徴量から似た商品を推薦する手法。協調フィルタリングのコールドスタート問題を一部回避できる。 |
| ホールドアウト検証 | 全データを訓練・テストに1回だけ分割する交差検証の方法。 |
| k-分割交差検証 | k回繰り返す交差検証。偏りを抑えやすいがホールドアウトより計算コストが高い。 |
| MSE・RMSE・MAE | 回帰問題の評価指標。MSEは誤差を2乗して平均、RMSEはその平方根、MAEは絶対値の平均。 |
| 第一種過誤・第二種過誤 | 偽陽性(FP)が第一種過誤(誤検出)、偽陰性(FN)が第二種過誤(見逃し)という統計用語。 |
| オッカムの剃刀 | 「必要以上に複雑な仮定を置くべきでない」というモデル選択の原則。 |
■ Reference(見覚えがある程度でOK)
| キーワード |
|---|
| ブートストラップサンプリング |
| 勾配ブースティング |
| 協調フィルタリング(コールドスタート問題) |
| マルコフ決定過程(MDP) |
| Q値・Q学習 |
引っかけ・誤解まとめ
第3章では、「用語の名前と用途のズレ」「指標の意味のすり替え」を狙った問題が多く出題されます。正しい知識を知るだけでなく、誤った選択肢を見抜く力が重要です。
- 【誤解】ロジスティック回帰は回帰問題に使う手法だ
-
理由:名前に「回帰」が入っているため
正解:分類問題に使う手法。出力を確率に変換してカテゴリを判定する - 【誤解】正解率が高ければ良いモデルだ
-
理由:「正解」という言葉で直感的に正しく見えるため
正解:クラス不均衡(例:不良品が0.03%)では正解率が高くても意味がない。適合率・再現率・F値を使い分ける - 【誤解】モデルの評価は訓練データで行えばよい
-
理由:手元にあるデータで確認するのが自然に思えるため
正解:訓練データでの評価は過学習を見抜けない。必ず未知のテストデータで評価する - 【誤解】適合率と再現率は同じ意味だ
-
理由:どちらも「正しさ」を測る指標に見えるため
正解:適合率は「予測した中の正確さ」、再現率は「実際の正例をどれだけ取りこぼさないか」。2つはトレードオフの関係にある - 【誤解】モデルは複雑にするほど良い
-
理由:複雑なほど表現力が高いと考えやすいため
正解:複雑すぎると過学習(オーバーフィッティング)になり、未知データに通用しなくなる - 【誤解】k-meansは分類問題の手法だ
-
理由:データを「グループに分ける」という点が分類問題と混同されやすいため
正解:正解ラベルなしで構造を見つける教師なし学習のクラスタリング手法。教師あり学習の「分類」とは異なる - 【誤解】教師あり・教師なし・強化学習には優劣がある
-
理由:精度が高そうな手法が「優れている」と見えやすいため
正解:優劣ではなく、問題の構造に応じて使い分けるもの。どれが最適かは問題次第 - 【誤解】AUCが高ければ必ず良いモデルだ
-
理由:AUCは1に近いほど良いという説明が単純化されて理解されやすいため
正解:AUCはモデルの「識別能力」を測る指標の一つ。問題の目的によっては再現率や適合率など別の指標を優先すべき場合がある - 【誤解】FPもFNも「見逃し」のことだ
-
理由:混同行列の用語は名前だけでは区別しにくいため
正解:FP(偽陽性)は「本当は負なのに正と判定した誤検出」、FN(偽陰性)は「本当は正なのに負と判定した見逃し」。病気検出や不良品検出では、FNの見逃しが特に問題になりやすい - ラッソ回帰とリッジ回帰は何が目的ですか?
-
どちらも線形回帰に正則化を加えた手法で、過学習を抑えることが目的です。細かい数式よりも「過学習への対策として正則化を加えたバリエーション」として押さえます。
- k-meansと階層的クラスタリングは何が違いますか?
-
k-meansはデータを横並びのk個のグループに分ける「非階層型」です。ウォード法や最短距離法は、クラスタ同士の階層構造まで求める「階層型」で、結果はデンドログラム(樹形図)で表されます。デンドログラムが問題に出てきたら、階層的クラスタリングを疑います。
次のステップ
第3章で「機械学習の手法と評価方法」の全体像がつかめました。
第3章はPart 2として単独の章です。次はPart 2のまとめ記事で第3章の重要テーマを一枚の地図に整理してから、Part 3(第4章・第5章)へ進みます。
Part 3では、いよいよディープラーニングの内部構造に踏み込みます。ニューラルネットワークがどう学ぶのか、誤差をどうやって逆向きに伝えるのか——機械学習の「手法の名前を知っている」状態から「なぜ動くのかが分かる」状態への移行です。
