AIはどのようにして「知能」を示すのか
―― 仕組みを整理しながら理解するための一つの見取り図 ――
はじめに
AIが人間のように「賢く振る舞っている」ように見える場面は、日常の中でも増えてきました。ただし、その振る舞いは魔法的なものではなく、いくつかの技術的な考え方の組み合わせによって説明されています。
生成AIパスポートの公式テキストでも、AIの知能的な振る舞いは特定の仕組みの上に成り立っているものとして整理されています。本記事では、その中でも基本となる考え方を中心に、全体像を確認していきます。
断定的な理解を目指すのではなく、「どの概念が、どの位置づけで説明されているのか」を整理するための足場として読み進めていただければと思います。
なぜこのテーマは分かりにくく感じやすいのか
AIの仕組みは、以下の要素が混在して説明されることが多く、初学者にとっては全体像をつかみにくい側面があります。
- 数学・統計の要素
- プログラムの考え方
- 人間の脳に例えた説明
また、「AI=学習する存在」というイメージが先行し、どのように学習しているのかが十分に整理されないまま理解が進んでしまうこともあります。
なぜ整理しておく価値があるのか
公式テキストでは、AIの仕組みは段階的に説明されています。そのため、個々の用語を覚えるよりも、「どの技術が、どの考え方に基づいて、どのような関係性で説明されているのか」を整理しておくことで、後から内容を確認しやすくなります。
本記事は、暗記用のまとめではなく、「戻ってきて確認できる基礎ページ」としての役割を意識しています。
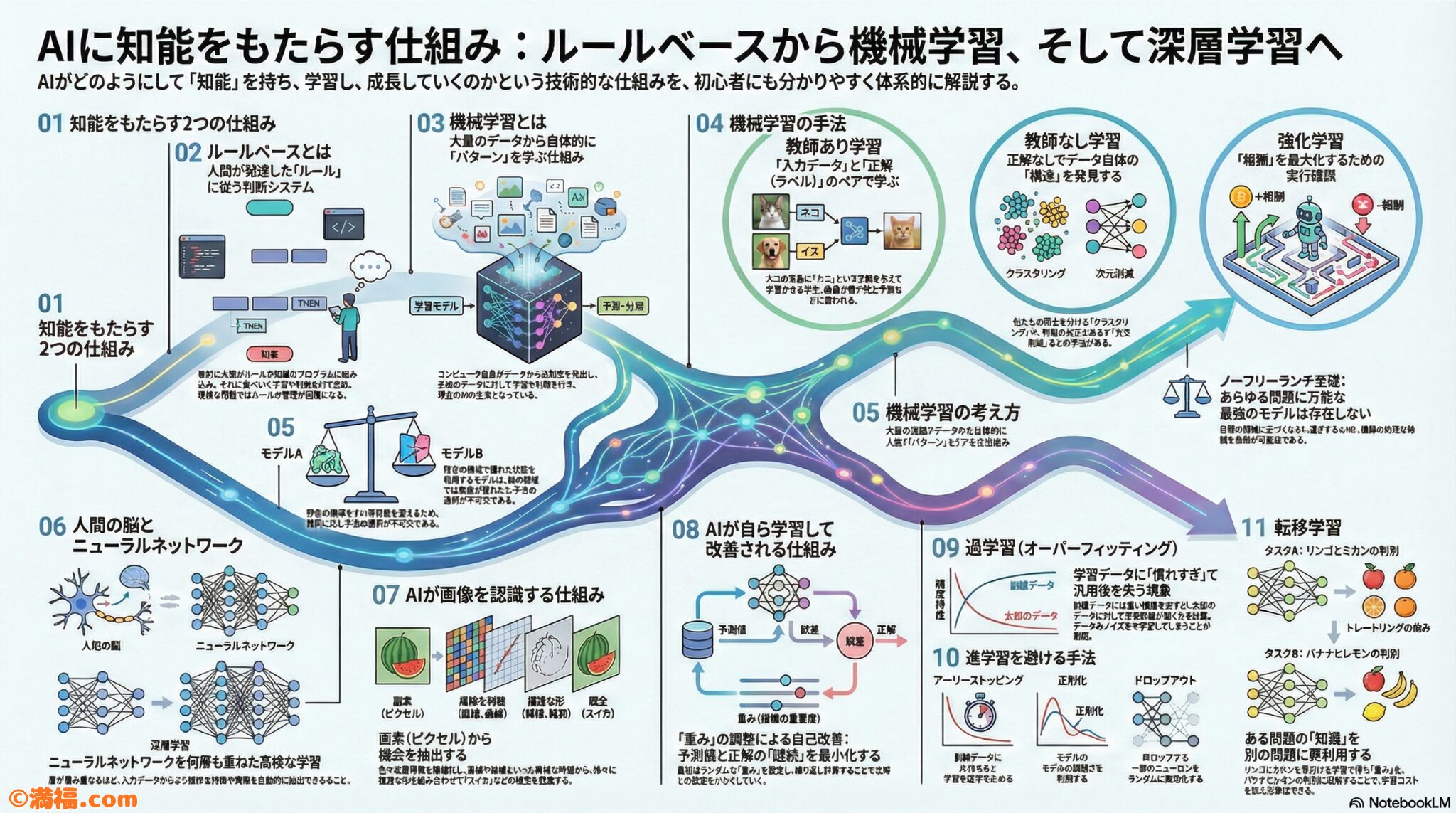
AIに知能的な振る舞いをもたらす二つの考え方
公式テキストでは、AIの振る舞いを実現する方法として、主に次の二つのアプローチが紹介されています。
- ルールベース
- 機械学習
これらは対立するものというより、考え方の違いとして整理されているものです。
1. ルールベースという考え方
ルールベースとは、人間があらかじめ判断基準となるルールを定義し、それをプログラムとして組み込む方式です。
- 「もしAならB」
- 「この条件を満たしたらこの処理を行う」
といった形で、判断の流れを人間が明示的に記述します。この方法は仕組みが分かりやすい一方で、以下の特徴があります。
- ルールの数が増えやすい(開発コストがかかる)
- 状況が複雑になるほど管理が難しくなる
2. 機械学習という考え方
機械学習は、ルールそのものを人間が書くのではなく、データからパターンを見つけるという考え方に基づいています。
この分野は、1959年にIBMの研究者である アーサー・サミュエル によって、次のように定義づけられました。
「明示的にプログラムされることなく、経験から学習する能力をコンピュータに与える学問領域」
大量のデータをもとに学習した結果は、学習済みモデル(Pre-trained model)と呼ばれ、画像認識や音声認識など、さまざまな分野で利用されています。
| 観点 | ルールベース | 機械学習 |
|---|---|---|
| ルールの作成 | 人間が記述 | データから抽出 |
| 入力の中心 | 知識・経験 | 大量のデータ |
| 振る舞いの決定 | 明示的な条件分岐 | 学習結果に基づく予測 |
機械学習の主な学習方法の分類
機械学習は、学習の進め方によって、いくつかの種類に分けて説明されています。
教師あり学習
入力データと正解データ(教師データ)をセットで与え、両者の関係性を学習する方法です。代表的な用途として以下が挙げられます。
-
[cite_start]
- 分類:画像に写っているのが「犬」か「猫」かを見分けるなど [cite: 189]
- 回帰:過去のデータから数値を予測する(売上予測など) [cite: 189]
[cite_start]
教師なし学習
正解データを与えず、データ自体の構造や特徴そのものを見つけ出す方法です。
-
[cite_start]
- クラスタリング:データを似た特徴を持つグループに分ける(異常検知などに応用) [cite: 206]
- 次元削減:多くの変数(特徴)を持つデータを、情報を保ったまま少ない変数で表現し直す [cite: 216]
[cite_start]
強化学習
行動の結果として与えられる「報酬」を手がかりに、試行錯誤しながら振る舞いを調整していく方法です(ゲームAIや自動運転など)。
試験対策としては、以下の用語も重要です。
-
[cite_start]
- 報酬:目的に近づくとプラス、遠ざかるとマイナスの評価を与える [cite: 228]
- 価値:各状態や行動の「良さ」を示す指標 [cite: 231]
- 方策:ある状態でどのような行動をとるべきかを示すルール [cite: 231]
[cite_start]
[cite_start]
半教師あり学習
教師あり学習と教師なし学習を組み合わせた考え方です。少量の「正解データ」と大量の「ラベルなしデータ」を併用することで、学習コストを抑える手法として説明されています。
「万能なモデルは存在しない」という考え方
機械学習の前提として、ノーフリーランチ定理という考え方が紹介されています。
これは、「ある問題に適した手法が、すべての問題に適しているとは限らない(万能なモデルは存在しない)」ということを示します。
そのため、目的やデータの性質に応じて最適なアルゴリズムを選ぶ視点が重要になります。
ニューラルネットワークと「脳」の模倣
現在のAIの中心技術であるニューラルネットワークは、人間の脳の神経細胞(ニューロン)のつながりを模倣したモデルです。
学習と「重み」の調整
脳のシナプス結合の強弱に相当するものを、AIでは「重み(weight)」と呼びます。
ニューラルネットワークにおける学習とは、出力結果と正解データとの差(誤差)を小さくするように、この「重み」を調整していく過程として説明されます。
AIは画像をどう見ているのか
AIが画像を認識する際、人間のように全体をぼんやり見ているわけではありません。画像を細かい画素(ピクセル)に分解し、それを数値データとして処理しています。
- 位置情報:画素がどこにあるか
- 色情報:RGB(赤・緑・青)の数値 [cite: 303]
[cite_start]
これらを特徴量として抽出し、形状やパターンを学習することで、「これはスイカである」といった認識を行っています。
過学習という現象とその対処法
学習を進めすぎると、過学習(オーバーフィッティング)という問題が起こります。
これは、学習データ(練習問題)には100点を取れるが、未知のデータ(本番の試験)には対応できない状態のことです。
公式テキストでは、これを避けるための具体的な手法として以下が挙げられています。
- アーリーストッピング:学習しすぎる前に、最適なタイミングで学習を止める。
- 正則化:モデルのパラメータ(複雑さ)を制限して、シンプルにする。
- ドロップアウト:ネットワークの一部をランダムに無効化(休ませる)して学習させる。
転移学習という知識の再利用
転移学習は、あるタスクで学習したモデル(知識)を、別の関連するタスクに応用する手法です。
例えば、「リンゴとミカン」を見分ける知識を、「バナナとレモン」の識別に活用するイメージです。これにより、学習時間の短縮や効率化が可能になります。
まとめ ― 概念の関係性を振り返る
本記事では、AIが「知能」を示すときの仕組みについて整理しました。
- アプローチ:ルールベース vs 機械学習
- 学習の種類:教師あり・なし・強化・半教師あり
- 仕組み:ニューラルネットワークと重みの調整
- 課題と対策:過学習とその回避策
どの用語も、単独で覚えるというより、「AIを賢くするための工夫」の歴史の中でどの位置にあるのかを確認しながら理解すると、試験対策としても盤石なものになります。