
PDF資料をGoogleドライブにアップロードして、
GoogleドキュメントでOCRをかけた時に、
こんな経験はないでしょうか。
- OCR後の誤字が多すぎる
- 図や表の中の文字が抜け落ちる
- 修正作業に想定以上の時間がかかる
GoogleドキュメントのOCRは手軽ですが、
資料の内容やレイアウトによっては精度が大きく崩れることがあります。
かといって、AdobeのAcrobat PROにサブスク料を払ってOCRするほどの使用頻度はないので、
チャッピーになにか良い手がないか聞いてみました。
ねえ、チャッピー。
Acrobat PROやOCR用のソフトを買わずに、PDFのOCR精度を高める方法はない?
あります。
ただし「OCRをうまくやる」という発想を、少し変える必要があります。
OCRがつらくなる本当の理由
多くのOCRツールは、PDFを画像として処理し、文字の形状から判定しています。
そのため、
- 解像度が低い
- 図表や注釈、本文が混在している
- 専門用語や固有名詞が多い
こうした資料では誤認識や順序の崩れが起きやすく、
結果として「OCR後に人が修正すること」が前提のテキストになりがちです。
発想を変える:AIに「読ませて復元させる」
ここでのポイントは次の通りです。
- 従来OCR:文字を「形」で拾う(拾えないと欠落する)
- AI読解:文字を拾いつつ、前後の文脈や資料内の整合から復元できる
OCRで文字が抜け落ちた場合、AIは
- PDF画像から読み取れる残りの字形
- 前後の文章の自然さ
- 同一資料内での用語の一貫性
- 専門用語としての出現傾向
などを手がかりに、もっとも整合する語を補完することがあります。
この性質が、「修正しないOCR」に近づける最大の理由です。
※注意:原文が潰れていて視覚情報が不足している場合、復元は推測に寄ります。
重要な箇所は、必ずPDF原本と突合して確認してください。
Google AI Studioを使うメリット
Google AI Studio(Pro系モデル)でPDFを扱うと、次のような違いがあります。
- 文脈を考慮した文字復元ができる
- 図や表の中の文字も拾える
- 専門用語や固有名詞が崩れにくい
- ページ構造を保ったまま出力できる
OCR後に「直す作業」を減らすのではなく、
最初から「直さなくていいテキスト」を取りにいく
Google AI StudioでPDFを高精度にテキスト化する手順
① Google AI Studioを開く
Google AI Studioにアクセスし、
トップ画面から「Chat with models」を選択します。
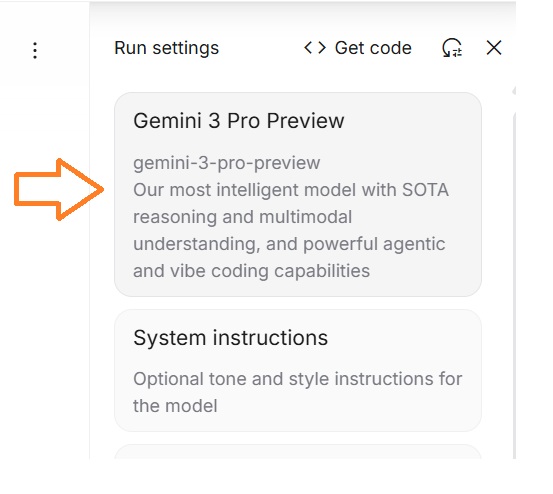
② モデルを「Pro」系に設定する(重要)
モデル名(Flashなど)をクリックし、
Pro系モデル(例:Gemini Pro / Gemini 3 Pro Preview)を選択します。
高速モデルよりも、一字一句の正確性を優先します。
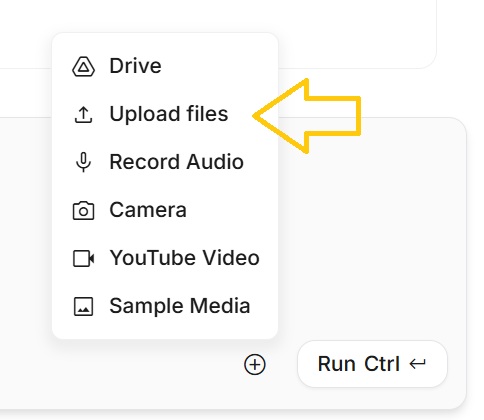
③ PDFファイルを直接アップロードする
入力欄横の「+」から「Upload from Computer」を選び、PDFをアップロードします。
Googleドライブ経由ではなく、PDFを直接渡すのがポイントです。

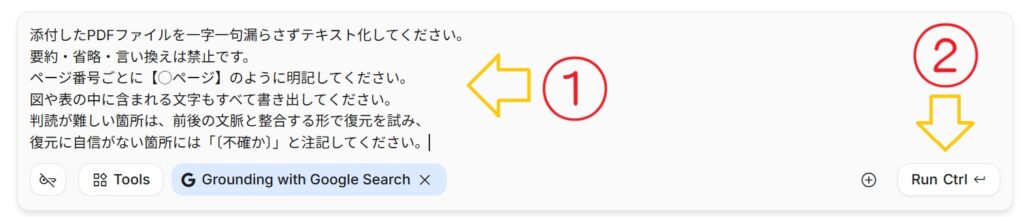
④ テキスト化の指示を出す
添付したPDFファイルを一字一句漏らさずテキスト化してコードボックスに出力してください。
要約・省略・言い換えは禁止です。
ページ番号ごとに【◯ページ】のように明記してください。
図や表の中に含まれる文字もすべて書き出してください。
判読が難しい箇所は、前後の文脈と整合する形で復元を試み、
復元に自信がない箇所には「〔不確か〕」と注記してください。
上のコードボックスのプロンプトをチャット欄にペーストして、チャット欄右側のRun Ctrlのボタンをクリックしてください。
⑤ 出力が途中で止まった場合
入力欄に「続けてください」と入力すれば、続きを出力してくれます。
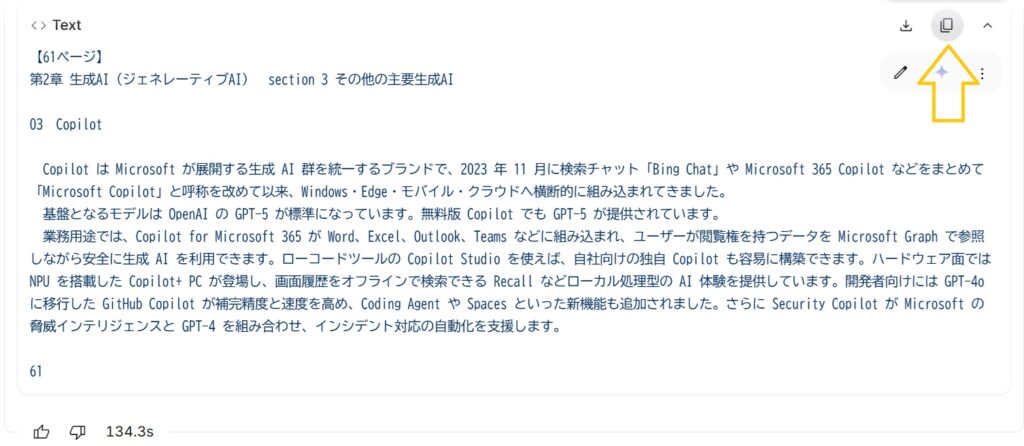
⑥ テキストを保存する
チャット欄のコードボックスにOCR後の文章が生成されたら、その文章をテキストエディタ等に貼り付けて保存してください。
⑦ 生成した文章と原本PDFの整合チェック
Google Geminiを開いて、OCR原本のPDFとそのPDFから生成したテキストを、Geminiにアップロードし、下記のプロンプトで諸折を実行してください。
アップロードしたPDFを原本。テキストを副本とし、副本の文章が原本の文章が整合しているか精査してください。読み飛ばしは禁止です。一語一句精査し、原本と副本の不整合が存在する場合は、副本内の不整合個所を示してください。⑧ 生成した文章の修正
Geminiが原本PDFとOCR副本を精査した結果、原本と副本の内容が整合しない場合は、下記のようなメッセージが表示されます。

Geminiの指摘に従い副本を修正する場合は、下記のGeminiに下記のプロンプトを与えて、副本を修正してください。
副本のテキストに対して、上記の不整合の修正を施した副本の全文を、コードボックスにテキスト出力してください。副本の不整合箇所が修正されたテキストを保存すればOCR作業は完了です。
さらに慎重を期す場合は、ChatGPTなどのほかのモデルに、原本PDFと修正した副本テキストの整合を精査させるとよいでしょう。
実際に得られるテキストの特徴
- 誤字や誤認識が大幅に減る
- 図表内の文字が欠落しにくい
- 抜け落ちた箇所が文脈に沿って復元されやすい
- ページ構成を把握しやすい
単なるOCR結果ではなく、
元PDFを再利用しやすいテキストデータとして扱える品質になります。
まとめ:AIの「復元力」を使う
従来のOCRは、拾えない文字はそのまま欠落します。
一方でAIは、PDFから読める情報に加え、
前後文脈の整合から復元を試みることができます。
これが、「修正しないOCR」に近づけるコツです。
ただし、復元には推測が混ざる可能性もあります。
重要な箇所だけは原本PDFと突合する。
この運用が、最も安全で現実的です。
