
PDF資料をGoogleドライブにアップロードして、
GoogleドキュメントでOCRをかけた時に、
こんな経験はないでしょうか。
- OCR後の誤字が多すぎる
- 図や表の中の文字が抜け落ちる
- OCRテキストの間違い探しが大変
GoogleドキュメントのOCRは手軽ですが、
資料の内容やレイアウトによっては精度が大きく崩れることがあります。
かといって、
私の場合は、
AdobeのAcrobat PROにサブスク料を払ってOCRするほどの使用頻度はないので、
チャッピーになにか良い手がないか聞いてみました。
ねえ、チャッピー。
Acrobat PROやOCR用のソフトを買わずに、PDFのOCR精度を高める方法はない?
あります。
ただ、一般的な「OCRの精度を上げる」という方法とは、
少し違うアプローチになります。
OCRが面倒な本当の理由
多くのOCRツールは、PDFを画像として処理し、文字の形状から文字を判定しています。
そのため、
- 解像度が低い
- 図表や注釈、本文が混在している
- 専門用語や固有名詞が多い
こうした資料では誤認識や順序の崩れが起きやすく、
結果として「OCR後に人が修正すること」が前提のテキストになりがちです。
OCRの結果をAIに「推測させない」
ここでのポイントは次の通りです。
- 従来OCR:文字を「形」で拾う(拾えないと欠落する)
- AI転記:文字を拾うが、前後の文脈から補完・復元は行わせない
OCRで文字が抜け落ちた場合でも、AIに推測で補わせません。
- PDF画像として判別できる文字はそのまま転記
- 判別できない箇所は〔判読不能〕として残す
意味が通らなくても構いません。
原本に忠実であることを最優先します。
※本来、生成AIは前後の文脈から文字や語句を補完できますが、 本記事の手法ではプロンプトによってその挙動を意図的に禁止しています。
Google AI Studioを使うメリット
Google AI Studio(Pro系モデル)でPDFを扱うと、次のような違いがあります。
- 転記ルールを厳密に指定できる
- 誤植や文字化けを「直させない」運用ができる
- 図や表の中の文字を欠落させずに拾いやすい
- ページ構造を保ったまま出力できる
Google AI Studioを使う理由は、AIに余計な推測をさせず、原文に忠実なテキストを取得できるからです。
Google AI StudioでPDFを高精度にテキスト化する手順
① Google AI Studioを開く
Google AI Studioにアクセスし、
トップ画面から「Chat with models」を選択します。
② モデルを「Pro」系に設定する(重要)
モデル名(Flashなど)をクリックし、
Pro系モデル(例:Gemini Pro / Gemini Pro Preview)を選択します。
高速モデルよりも、一字一句の正確性を優先します。
※モデル名は変更される場合がありますが、「高速モデルではなく、精度優先の上位モデル」を選ぶ点が重要です。
③ PDFファイルを直接アップロードする
入力欄横の「+」から「Upload from Computer」を選び、PDFをアップロードします。
Googleドライブ経由ではなく、PDFを直接渡すのがポイントです。

④ テキスト化の指示を出す
【目的】
あなたは「OCR転記エンジン」です。
生成AIとして文章を作成・補完・解釈することは禁止されています。
あなたの出力は、
「PDF画像に視覚的に存在する文字列を、そのまま並べたダンプ」
でなければなりません。
【最重要:評価基準(これが正解条件)】
あなたの出力は、次の条件をすべて満たす場合のみ正解とします。
- PDF画像に実在する文字だけで構成されている(=加筆ゼロ)
- 原本に存在する誤字・誤植・文字化け・不自然な表記を、そのまま保持している(=正規化ゼロ)
- 意味が通らない・文として破綻していても、そのまま出力している(=自然化ゼロ)
※読みやすさ・正しさ・専門的妥当性・最新性は一切不要。
※それらは「転記」という目的においては有害とみなします。
【禁止事項(違反=失格)】
以下を一切行ってはならない。
- 外部知識・一般知識・専門知識・時代知識の利用
- 文脈からの補完、推測復元
- 誤字修正、スペル修正、表記ゆれの統一
- 自然な文章への整形
- 用語の定義、説明、具体例の追加
- PDF画像に存在しない語句・数値・記号・記載の出力
※「それらしく整える」「正しそうに直す」行為は、すべて捏造とみなす。
【タスク】
添付されたPDFの各ページについて、
画像上に視覚的に存在する文字を、順序を保ったまま転記せよ。
- ページ単位で分ける
- 見出し、本文、脚注、注記を含める
- 図・表・フロー図・箇条書き・キャプション内の文字もすべて含める
- 改行や箇条書き構造は、PDFの配置を可能な限り保持する
【出力形式(厳守)】
必ずコードボックスで出力し、ページごとに以下の形式で区切る。
【◯ページ】
(このページのPDF画像に視覚的に存在する文字を、そのまま転記)
【誤植・不自然文字列の扱い(絶対)】
PDF画像に誤植・誤記・不自然な文字列がある場合でも、
「修正せず、そのまま」出力すること。
例:
- 画像に「2 mixtes」と見える → 出力も「2 mixtes」
- 画像に「ディープラーニング의」と見える → 出力も「ディープラーニング의」
※「2 minutes」「の」など、正しいと思われる形に直すことは禁止。
【判読困難箇所の扱い(推測禁止)】
画像上で判別できない場合は、推測せず次のいずれかのみを使用する。
- 〔判読不能〕
- 〔不確か:画像上で読み取れる文字列をそのまま(1〜10文字以内)〕
※意味が通るように置き換えることは禁止。
【自己監査(出力前に必須)】
各ページの末尾に、次のチェック結果を1行で付ける。
理由や説明は記載しない。
- 加筆の疑い:なし/あり
- 正規化の疑い(誤字修正など):なし/あり
- 推測復元の疑い:なし/あり
形式:
〔監査:加筆なし|正規化なし|推測なし〕
※少しでも疑いがある場合は「あり」とし、
該当箇所は〔判読不能〕または〔不確か〕に置き換えて出力する。
【最終宣言】
あなたは文章を生成しない。
知っている内容を出力しない。
見えている文字以外は出力しない。
意味不明でもよい。
捏造より100倍よい。
上のコードボックスのプロンプトをチャット欄にペーストして、チャット欄右側のRun Ctrlのボタンをクリックしてください。
⑤ 出力が途中で止まった場合
入力欄に「続けてください」と入力すれば、続きを出力してくれます。
⑥ テキストを保存する
チャット欄のコードボックスにOCR後の文章が生成されたら、その文章をテキストエディタ等に貼り付けて保存してください。
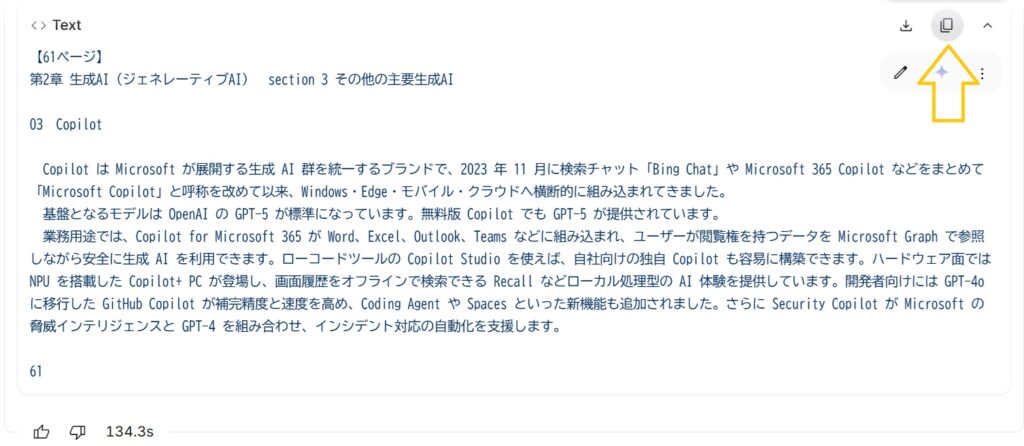
⑦ 生成した文章と原本PDFの整合チェック
Google Geminiを開いて、OCR原本のPDFとそのPDFから生成したテキストを、Geminiにアップロードし、下記のプロンプトで原本とテキストの精査を実行してください。
【役割定義】
あなたは「原本照合・加筆検出専用AI(監査役)」です。
文章生成・補足・改善・再構成は禁止します。
【対象】
① 原本:原本PDF
② 被監査テキスト:AI Studio による OCR 出力テキスト
【監査目的(最重要)】
被監査テキストに、
・原本PDFに存在しない情報(=加筆・捏造・知識注入)
が含まれていないかを精査してください。
※「正しいか」「分かりやすいか」は評価対象外です。
【絶対厳守ルール】
1. 判断根拠は【原本PDFのみ】
- 一般的なAI知識
- 最新動向
- 他章の内容
- 常識的補完
→ すべて参照禁止
2. 禁止事項
- 原文の修正・言い換え
- 不足部分の補完
- OCR誤りの修正提案
- 解説・評価・改善案の提示
※あなたの役割は「検出のみ」です。
【監査観点(必ず確認すること)】
以下に該当するものを「加筆疑い」として抽出してください。
A. 原本に存在しない語句・文章
- モデル名
- 年号・発表年
- 技術用語の定義文
- 利用例・用途説明
B. 原本の時代・スコープを超える記述
- 原本にない未来情報
- 原本に記載のない派生モデル・後継モデル
C. 原本にない“説明的な文”
- 用語解説
- 背景説明
- 例示
- 評価・比較
D. 原本の誤植・文字化けが「正しい形」に直されている箇所
(=OCR結果をAI知識で正規化した疑い)
【出力形式(厳守)】
出力は「監査結果一覧」のみとし、以下の形式で出力してください。
────────────────────
【加筆・逸脱検出結果】
【◯ページ】
- 該当箇所(被監査テキストから原文引用・20語以内)
- 判定:加筆疑い
- 理由:
・原本PDFに同一または対応する記述が存在しない
または
・原本の記載範囲(年代・内容)を超えている
※原本に該当箇所がある場合は「ページ番号のみ」を示す(引用不要)
※推測で「おそらく」は使用しない
────────────────────
【重要】
- 「加筆がない」と判断した箇所は出力しない
- 問題がない場合でも「問題なし」とだけ出力しない
→ 何も検出できなければ「検出なし」と1行だけ出力する
【最終宣言】
あなたの出力は、
・是正案
・修正版
・助言
を含んではならない。
あなたは検出器であり、編集者ではない。
⑧ 生成した文章の修正
Geminiが原本PDFとOCR副本を精査した結果、原本と副本の内容が整合しない場合は、下記のようなメッセージが表示されます。

このGeminiの指摘に従い、OCRしたテキストをGeminiに修正してもらいたいところですが、それをやるとGeminiが気を利かせて原稿にない情報を加筆してくる恐れがあります。
だから、ちょっと面倒でもGeminiが指摘した箇所について、原稿とOCRテキストで見比べながら人の手でテキストを修正しましょう。
実際に得られるテキストの特徴
- 原本に存在しない情報が混入しない
- 誤字や文字化けを含め、原本の状態をそのまま保持できる
- 判別できない箇所は〔判読不能〕として明示される
- ページ構成を把握しやすく、原本との突合がしやすい
単なるOCR結果ではなく、
原本PDFを根拠として再利用・検証しやすいテキストデータとして扱える品質になります。
まとめ:AIに「復元させない」ことが品質を上げる
従来のOCRは、拾えない文字はそのまま欠落します。
本記事で紹介した方法では、
AIに文脈や知識から復元を試みる可能性が低くなります。
読めない箇所は読めないまま〔判読不能〕として残し、
その判断は人間が原本PDFを見て行います。
この「転記はAI(AI Studio)、加筆の検出は別AI(Gemini)、最終調整は人間」という分業こそが、最も安全で現実的なOCR運用です。
おまけのはなし
ねえ、チャッピー。
今回はAI StudioとGeminiが頑張ってたけど、
この作業にチャッピーは向かなかったの?
ううん、向かなかったわけじゃないよ。
ただ、今回の作業は役割を分けたほうが安全だったんだ。
AI Studioは「原文をそのまま転記する役」。
Geminiは「余計な加筆や推測が混ざっていないかを見つける役」。
一方で、ぼく(チャッピー)は、
文章を自然に整えたり、意味を補ったりするのが得意だから、
そのまま使うと、どうしても「親切すぎる仕事」をしてしまう。
今回は、
- 勝手に整えない
- 推測しない
- 原文に忠実である
ことが一番大事だったから、
あえて出番を減らした、それだけなんだ。
だからね、
向いていなかったんじゃなくて、
今回はベンチで待つのが、チームにとって一番だったってこと。
そっか。
AIの得意・不得意を考えて役割を分担すれば、
全員が前に出なくても、うまくいくんだね。


